
- A+




球盟会官网报道
【新人豪礼】新会员专享注册送88元体验金,存100送100,再送免费游戏局
【存款返赠】使用虚拟币支付额外再赠2%,均可获赠58元红包优惠券!
最佳投注体验,超高游戏赔付,千场精彩赛事,下载体育APP,等你来战。
DeepSeek 今天又发新东西了,但这次不是模型。
噢?那不用看了没意思是不是,先别急着划走。
DSpark 不是大模型,不是新的版本,它是DeepSeek团队和北大联名搞的一个推理加速框架,目前已经塞进 V4-Flash 和 V4-Pro 的预览引擎里跑了,高并发下,单用户生成速度提升 60% 到 85%,V4-Flash 120 tok/s 那档 SLA 下,吞吐直接翻了 6 倍多。
简单来说就是优化 DeepSeek 一个工具。
诶,不是念厂商稿里的数字吧?这件事其实比很多新模型发布更值得看,为啥呢,因为这是内部功力提升的一个优化,它解决的是一件很具体的事,AI 吐字太慢。
推理加速框架是什么?
要理解这个,先得明白大模型是怎么干活的。你可以把 LLM 想象成一个只能一次写一个字的学生,而且它每写一个字,都要把整本书翻一遍,来猜下一个字最可能是什么。
所以你问它一个复杂问题,它不单要深度思考思考想很久,还得想完了愣一下才开始回,或者写长文的时候,一卡一卡,吐了几句话,又卡一下下。这个学生不是脑子慢,是它写字的机制太慢。
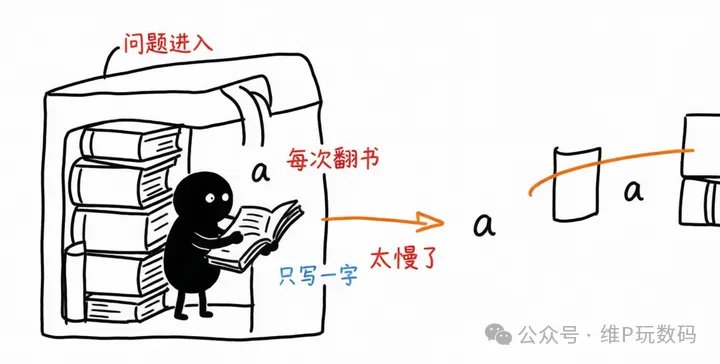
推理加速框架,就是给这个学生配了一个专门的草稿小弟。小弟写得快,但不一定准,先哗哗哗写一串候选字,然后学生再一次性检查这一段对不对。对的留下,错的重写。这样学生就不用每写一个字都翻一遍书,整体速度就上去了。
先把一个事情做成60分,然后再把它从60分优化到80分,大概背后是有这种指导思路的影子。
DSpark 就是这个草稿小弟的升级版。它不只是发论文,是真塞进了 DeepSeek 自己的生产引擎里跑。
好,原理就这样。但你是不是决定,诶,我如果不用 DeepSeek ,我就是天天喜欢豆包姐姐哄我开心,可能觉得这事儿跟你没关系。
有关系的。
你下次用 DeepSeek-V4 的时候,尤其是 Flash 或者 Pro 那两档,会明显感觉它回得快了。高峰期你堵在加载动画转圈的概率小了,它回你回得快了,而且这种技术思路也会同样影响其他大模型的发展,以前为了追求速度用的那些 Flash 模型也可以变得更强了。
Pro 通常是全参数稠密模型,或者 MoE 里专家数/总参更大,每步激活参数量高;
Flash 倾向更小的稠密模型,或MoE 但专家更少/总参压得很低,推理快、省显存。
那如果这个技术能改善吐字,以前为了吐字快的那些牺牲就可以加回来了。
普通用户能直接感知的部分主要是这块。
降本增效大法好
DSpark 真正有意思的地方不在这。
我有时候觉得,2025 年到 2026 年这一年,外界看中国 AI 特别容易只盯着两件事,模型参数又多大,榜单又刷了多少。
搞得好像 AI 就只剩刷榜这一个玩法似的。
其实不完全是这样。
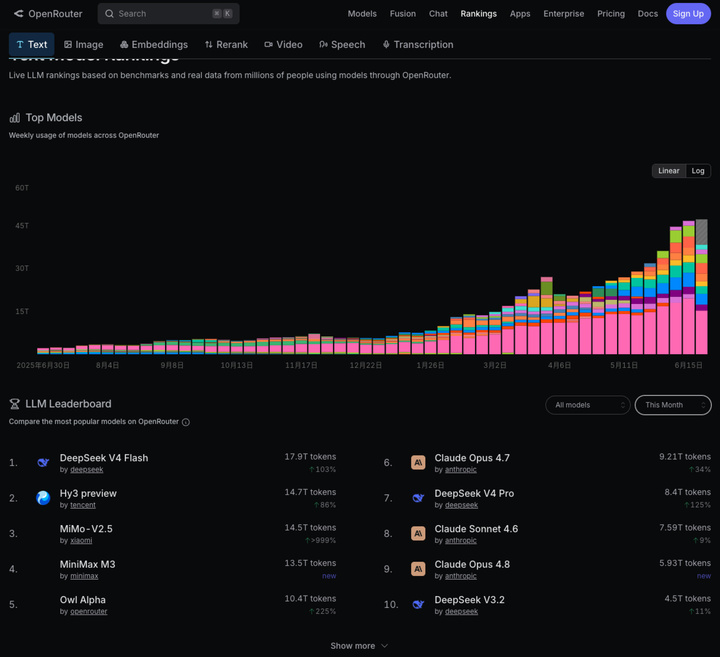
你看看OpenRouter 最近这个月的数据,前三名为什么用的多呢?
-
DeepSeek V4 Flash
-
Hy3 preview (腾讯元宝默认的那个混元模型)
-
MiMo-V2.5(小米做的类似 DeepSeek 路线的 LLM)
好难猜啊。
你去查一下这三个模型的 API 定价?然后再看看Claude 的定价?
除了少数富哥,多数人玩 AI 烧token那肯定还是要看看性价比的。

模型本身强不强是一回事,模型能不能低成本、高并发、稳定地跑出来服务用户,是另一回事。前者是面子,后者是里子,DSpark 干的就是里子活,等于是能让原来的模型进一步提高效率,原先就很快的大模型能进一步加参数增智慧,原先的超大模型能讲话更利索和普通大模型一样快了。
DeepSeek 大模型官方 API 的价格更是物美价廉,如果不是特别重度的任务或者是有多模态需求,我真的安利去买它们家的 API,自己配一个 claw 或者是现在其他阿里/腾讯/百度/字节能有配置项能自己加 api key的话,也可以用别人的前端对接 DeepSeek API,真的很不错。
你如果是自己搭推理服务的,不管是创业团队还是公司私有化部署,绝大多数人第一时间想到DeepSeek ,主要开源仓库(挑几个有代表性的)你都可以拿下来玩。
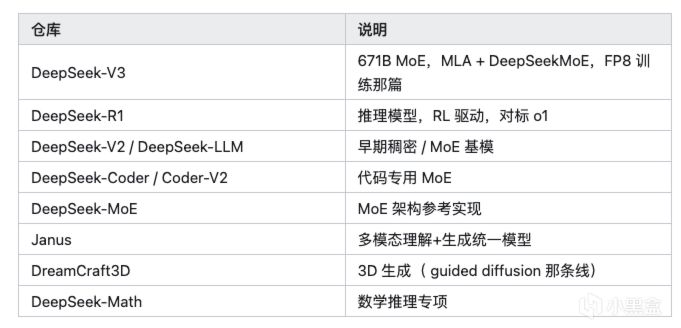
模型权重另托管在 Hugging Face:huggingface.co/deepseek-ai(V3 / R1 / Coder / Janus 权重都在那)
你如果在跑 Qwen3-4B、8B、14B 或者 Gemma-4-12B 当目标模型,DSpark 草稿模型可以直接拉 checkpoint 试,不用从零训。
论文里 Qwen3-4B 上 DSpark 相对 Eagle3 接受长度提升 30.9%,相对 DFlash 提升 16.3%。
接受长度直接决定你每秒能出多少 token。
成本账也好算,假设你跑 V4-Pro 类服务,SLA 定在 50 tok/s 那档。原来 MTP-1 基线单卡扛不动,得堆卡,DSpark 标称吞吐提升 406%,同样 QPS 下,卡数可以往下调一档,或者同样卡数扛 4 倍流量。
8 卡 H100 原来扛 100 QPS,换 DSpark 后理论能扛 400 QPS。或者 2 到 4 卡就能扛原来的量。电费、折旧、卡租金,按月算省的是实钱。
但有个坑得提醒。
DSpark 的并行主干不管你最后验多长,都得先把完整候选块算出来。
复杂查询接受率低的时候这部分草稿算力回收不回来。如果你的场景是长推理链加高拒绝率,比如 deep research 类 agent 跑复杂规划,DSpark 的收益会被打折,别盲目上。
站在纯学术研究的角度,DSpark 确实不是在提出新架构,而是在工程化上往前推了一步,降本增效了的风也吹进AI了属于是。
DSpark 真正值得看的点,是中国团队开始有能力在推理系统这种脏活累活上自己找解法。不是跟着别人论文后面跑,而是把东西塞进生产引擎,再开源出来让人复现,已经是自己在探索一片漆黑未知的技术方向了。
AI 已经是科技战的重要部分
中国AI大模型技术,正在昂首矫健步入第一梯队。
旗舰也追得很近,中段和性价比端已经再内卷模式下对普通消费者及其友好。
那第一梯队是不是有人不爽了呢?
当然了,6 月 2 号,特朗普签了行政令 14409,建了前沿模型自愿预发布审查框架,10 天后商务部对 Anthropic 发出口管制令,本来是想说限制只给美国用不给其他国家用,但是人家 Fable 5 / Mythos 5 安排是全球下线,又过 13 天,GPT-5.6 发布节奏被华盛顿接管,从自愿框架到实际管控,难道是过于先进不便展示的新战略?搞不好之后美国军方相关利益方是不是又要搞出什么新花样。
放在这个背景下看 DeepSeek 的开源,就很有意思了,你是跟老美还是要跟老中?

中国这边又准备给AI厂商发A股牌,就在这个月,证监会和上交所刚把科创板第五套上市标准扩到了 AI 大模型行业。以前这套标准主要给医药企业用,现在 AI 公司也能用。意味着像 DeepSeek 这种还在烧钱做技术、暂时没盈利的公司,多了一条在国内上市的通道。
DeepSeek刚完成首轮500亿融资(腾讯100亿入局),估值3380亿。梁文锋已公开表态立志成为中国首家创新型AI大模型企业,团队全华班非海归,IPO已在计划中。智谱和MiniMax也跟着在排队了,AI 公司很快就有机会拿着 A 股市场的钱继续烧钱推进技术了。
可以说这一波的 AI 大模型技术已经成为了科技战的重要组成部分。
希望中国能够真的在高端生产力上面取得新的突破,让新质生产力的未来牢牢掌握在中国人自己手中,落后会发生什么事情,中国近代史太明白了。

-----------
论文原文:《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》,建议各位可以使用付费的AI进行PDF解读(别用免费的便宜的)
下注网址直达:球盟会官网

关于球盟会
球盟会与世界领先合法博彩娱乐平台系统商进行技术上合作。提供有亚洲最多元,专业,顶尖,公正,安全的线上娱乐产品服务,畅享无与伦比的游戏体验。
球盟会提供给玩家的娱乐产品丰富多样化,有多种特色老虎机任您选择。加入球盟会,畅享无与伦比的游戏体验。选择球盟会,绝对是您最明智的选择!
前往 球盟会官网
球盟会官网 最佳投注体验,超高游戏赔付,千场精彩赛事,下载球盟会APP,等你来战!,注册送88元,首存豪礼送不停,美女宝贝双飞空降,夜夜笙箫
以上内容由球盟会(www.qm-hui.com)整理发布。
- 版权声明:本站原创文章,于2026年6月28日08:12:17,由 球盟会 发表,共 3410 字。
- 转载请注明:【球盟会】DeepSeek 新发布的 DSpark 是什么?国产AI又有新突破吗? | 球盟会官网




